A distro based on the xbps packaging system
All Void managed mirrors now listen on new primary addresses. The default mirrors have been updated in the xbps package and will take effect on your next system update. If you were manually setting mirrors, please take a few moments to update the hostname you have configured.
Now is also a great time to determine if you’re using the nearest mirror. An up-to-date list of mirrors and locations can be found any time at http://auto.voidlinux.org/?mirrorstats.
Please report issues at https://github.com/void-linux/xbps/issues.
A new XBPS stable version has been released: 0.53. This is a minor release that contains bugfixes and performance improvements:
xbps-rindex(1): fix possible stagedata deadlock. (@Gottox)
xbps-create(1): Allow file paths longer than 128 characters. (@Gottox)
libxbps: share workload more efficient between threads and avoid idling threads. (@Gottox)
xbps-rindex(1): By default xbps-rindex will not check hashes while cleaning. To enable the old behavior the user can supply the –hashcheck flag. (@Gottox)
This version also bumps the ABI version that should’ve happened with 0.52. Sorry for that.
Please report issues at https://github.com/void-linux/xbps/issues.
So we’re finally moving our GitHub Organisation. The new organisation name will be github.com/void-linux.
We will move the organisation on 2018-06-15.
This is a painful but important step in our reorganisation procedure and lays the foundation of expanding our maintainer team.
Beginning from that date, Void will only accept new pull requests for our new org. New pull requests opened on the old organisation will be auto closed. The remaining pull requests on the old organisation will remain open and will be handled, or the author can reopen them on the new org.
We will add a comment to the remaining issues asking for them to be reopened on the new organisation.
During the next few weeks the team will publish updates to point the repositories to voidlinux.org instead of voidlinux.eu. We will publish a dedicated news entry when the domain is ready to be used.
For everyone that manually configured a repository under the voidlinux.eu domain, please change it manually.
The voidlinux.eu domain will continue to work, but we cannot give any promises for how long.
At last we’d like to thank for the awesome support we’re experiencing during our restructuring.
A quick follow-up to yesterday’s post: We have control over the IRC Channels again!
Thank you Freenode support team!
Dear Void Users,
We have a problem. In the last few months people have been complaining about the lack of management capabilities in the Void Core Team. We have been aware of the problem, and it’s time to explain the situation.
The current project leader has disappeared. We have had no contact with him since the end of January, and no meaningful contact for well over a year. This itself would be concerning, on its own but no threat to the project.
The problem is that we currently have no ability to manage some of Void’s central resources. In the past, they were managed exclusively by the former project leader. Namely:
We contacted Github, but they declined any help to regain access to the organisation. This is really really unfortunately as Github grew to a tool for both source and community management. This has led to questions of if Github is still the best option for us, but we are continuing with the platform for the foreseeable future.
We have contacted freenode support. We see hope to regain access to the VoidLinux IRC Channels. IRC is an essential tool for communication of the core team.
We regained partial control over voidlinux.com. But the most used domain, voidlinux.eu, is currently not under our control. It currently works, but as soon as we have to move any IP addresses, it will fail. IP addresses may need to be moved for a variety of reasons, the most obvious being when we upgrade the master build server.
Currently we are in limbo and are trying to get back on track. We see no possibility to regain access to the Github organisation. So for Github, we will move to a new organisation.
We have a similar solution for the domains. We will move to a different domain and continue to support the voidlinux.eu domain as long as possible.
For the IRC Channels, we will try to get in contact with freenode and regain access. We are hoping that freenode support will be open to our request.
We learned our lesson. In future no single person will have exclusive access to Void’s resources.
Furthermore, we’re in contact with a non profit organisation that helps open source projects to manage donations and other resources. We hope that we can announce further details in a few weeks.
For now, just be aware that the engineering work to help mitigate our problems is underway. This engineering work is consuming the full resources of 2 senior contributors, and has unfortunately also led to longer PR review times..
If you have any questions, you can contact us via the forum, Twitter, or IRC.
A new XBPS stable version has been released: 0.52. This is a major release that a few new features and bugfixes:
Because many ponies enjoyed the The Advent of Void: Day 25: ponysay post we decided to release a new Void Linux image with all your friends onboard.

Happy eastern to everypony!
Who of you ever wanted a pony for Christmas? Turns out, Void Linux already includes some. Don’t worry, they are just virtual yet just a command away:
# xbps-install ponysay

ponysay features over 400 illustrations of My Little Pony for your terminal. Look at all of them using
% ponysay-tool --browse /usr/share/ponysay/ponies
You even can make the ponies quote themselves using ponysay -q.
Lots of fun for everypony! Whee!
cron(8) is a nice tool, but it has some long-standing problems, among them:
%?).A little, but flexible alternative is to use snooze(1), which essentially just waits for a particular time, and then executes a command. To get recurring jobs ala cron, we can use this together with our runit service supervision suite. If we wanted at(1) instead, we can just run snooze once.
The time for snooze is given using the options
-d (for day), -m (for month), -w (for weekday),
-D (for day of year), -W (for ISO week), and
-H (for hour),
-M (for minute),
-S (for second).
Each option of these can be comma-separated list
of values, ranges (with -) or repetitions (with /).
The default is daily at midnight,
so if we wanted to run at the next full hour instead, we could run:
% snooze -n -H'*'
2017-12-24T17:00:00+0100 Sun 0d 0h 47m 33s
2017-12-24T18:00:00+0100 Sun 0d 1h 47m 33s
2017-12-24T19:00:00+0100 Sun 0d 2h 47m 33s
2017-12-24T20:00:00+0100 Sun 0d 3h 47m 33s
2017-12-24T21:00:00+0100 Sun 0d 4h 47m 33s
The -n option disables the actual execution and shows the next five
matching times instead.
To run every 15 minutes, we’d use
% snooze -n -H'*' -M/15
2017-12-24T16:15:00+0100 Sun 0d 0h 1m 31s
2017-12-24T16:30:00+0100 Sun 0d 0h 16m 31s
2017-12-24T16:45:00+0100 Sun 0d 0h 31m 31s
2017-12-24T17:00:00+0100 Sun 0d 0h 46m 31s
2017-12-24T17:15:00+0100 Sun 0d 1h 1m 31s
More complicated things are possible, for example next Friday the 13th:
% snooze -n -w5 -d13
2018-04-13T00:00:00+0200 Fri 108d 6h 45m 33s
2018-07-13T00:00:00+0200 Fri 199d 6h 45m 33s
no satisfying date found within a year.
Note that snooze bails out if it takes more than a year for the event to happen.
By default, snooze will just terminate successfully, but we can give it a command to run instead:
% snooze -H'*' -M'*' -S30 date
Sun Dec 24 16:27:30 CET 2017
When snooze receives a SIGALRM, it immediately runs the command.
snooze is quite robust, it checks every 5 minutes the time has progressed as expected, so if you change the system time (or the timezone changes), it is noticed.
For additional robustness, you can use the timefiles option -t,
which ensures a job is not started if its earlier than some
modification time of a file. On success, your job can then touch this
file to unlock the next iteration. Together with the slack option
this can be used for anacron-style invocations that ensure a task is
run, for example, every day at some point.
Day 23, almost the end of the year. You may consider that it’s time to look
back and take stock of your month, or your year. An accounting, if you will.
Fortunately we have a package or two for that: ledger and hledger. The
second one is a rewrite of the first in Haskell, while the first is the one
that sets the spec.
I must apologize in advance: I am not an accountant, so I may confuse the powerful concepts on which accounting depends. Please bear with me, and feel free to let me know of any corrections.
These are accounting tools, with powerful features I never need to use, web interfaces I don’t need (but maybe others in our lives would desire), but are easy to use with text files with a simple format.
To pass a file to ledger (or hledger), just call ledger -f
path/to/ledger.file, and make sure the file contains entries (or even just
one) of the format:
2017-12-25 My true love gave to me
Equity:TrueLove -1 partridge
Assets 1 partridge
The notion behind the ledger format is the same as double entry accounting. What goes in must come out, or everything must come from somewhere. If you take $5 from one place, it has to go somewhere else, in that same transaction.
2017-12-26 My true love gave to me and I paid back Tom
Equity:TrueLove -2 turtledove
Assets 1 turtledove
Assets:Tom 1 turtledove
For instance, the following ledger entry will throw an error because nothing matches!
2017-12-27 My true love gave to me
Equity:TrueLove -$3
Assets $1
Assets:Tom $1
(I switched to units where I could be certain the double entry mechanisms are checked. They don’t seem to be for french_hens.)
The ledger manual has a lot of information about all the things ledger supports, including inline maths and stock prices.
May your books forever be balanced!
We already covered other cleaning tools like
ncdu and probably everybody used some form of
du -h ... | sort -h as well, but there is another little gem I’d like you to know
about.
QDirStat uses a treemap to display used disk space.
# xbps-install qdirstat
Files are represented as little boxes. The color hints the file type and the area covered corresponds to the file size. Then QDirStat tries to group files within a folder into one rectangle. This is done for the whole hierarchy. The per-folder cushion shading guides your eyes and makes it easy to recognise related files.
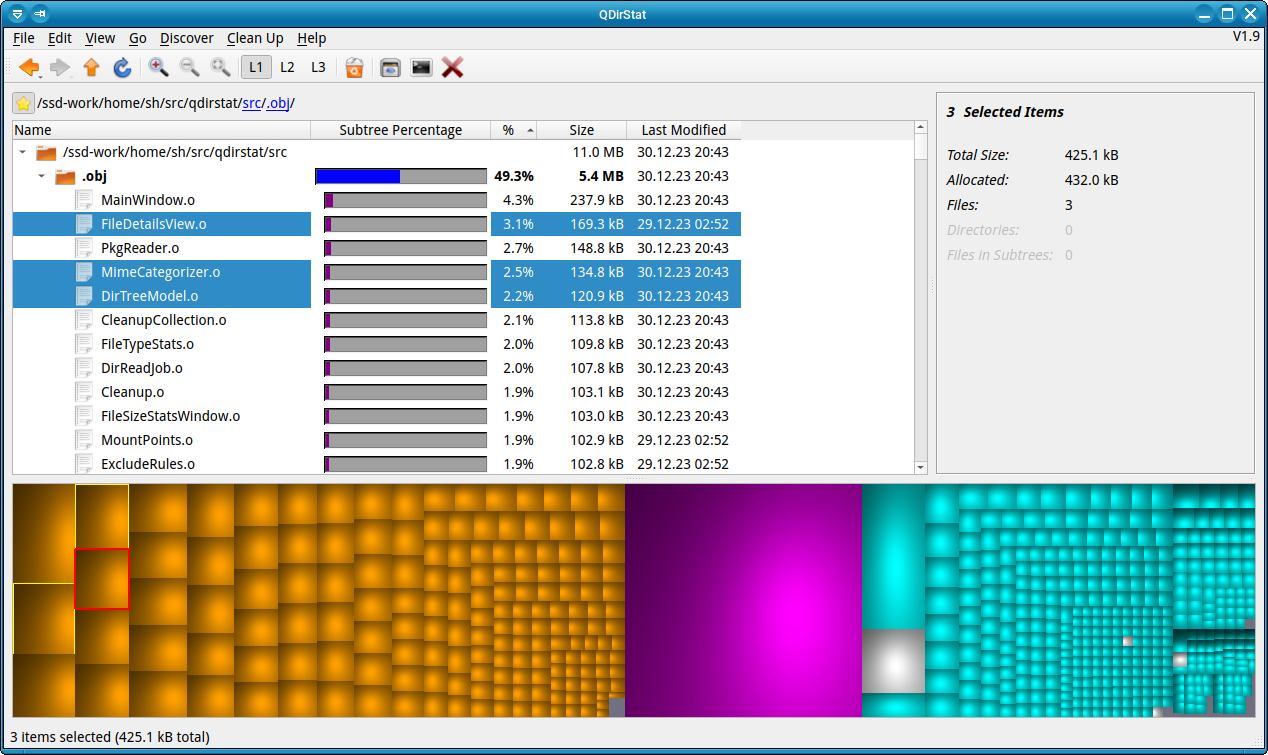
The treemap is interactive. To find what file belongs to a box, you can just
click on it. With the Alt + ↑ shortcut, you can go one level up in the file
hierarchy. At the same time a box is painted around the whole folder.
With qdirstat-cache-writer (separate package, minimal dependencies) you can
collect file sizes on remote or headless machines.
On the remote machine install the package and scan your disk with:
# xbps-install qdirstat-cache-writer
# qdirstat-cache-writer /path/of/interest cache-file.cache.gz
You can transfer the cache-file via ssh or any other method and just throw it
against qdirstst locally:
# scp remote:/path/to/cace-file.cache.gz .
# qdirstat --cache cache-file.cache.gz
You can still examine the hierarchy, but you loose the ability to run the clean-up actions.
At the time of writing QDirStat had no open issues or pull requests. I’m not aware of any obvious bugs. It’s a unique and solid tool. My disks thank Stefan Hundhammer for his amazing work.
On Void, we have many clones of beloved vi(1) such as vim, neovim, nvi, vile, busybox vi, and of course the original ex-vi.
But today, I want to talk about neatvi, a reimplementation from scratch with minimal footprint (fewer than 6kLOC); it doesn’t even need ncurses! Nevertheless, it supports UTF-8, and even editing bidirectional text, and generally has a good coverage of the POSIX vi feature set.
Of course, it doesn’t provide all the bells and whistles of vim and friends, but it adds a few important features on top of plain vi, such as infinite undo/redo, basic syntax highlighting, and a partial implementation of ex(1).
It’s a nice editor for limited environments such as embedded devices or recovery systems, or for people that like unbloated software.
When you have multiple machines, sometimes you’ll want to run the same
commands on all of them. There are many tools for this job, starting
from simple for loops on the shell to full-fledged configuration
management systems such as Puppet or Chef.
A good compromise is shmux(1), the shell multiplexer.
For example, we can measure the uptimes of my servers,
passing the command with -c:
% shmux -c uptime vuxu.org root@epona.vuxu.org hecate.home.vuxu.org
vuxu.org: 15:48:01 up 91 days, 6:05, 45 users, load average: 0.55, 0.47, 0.40
root@epona.vuxu.org: 15:48:07 up 502 days, 19:29, 1 user, load average: 0.37, 0.29, 0.29
hecate.home.vuxu.org: 15:48:03 up 225 days, 5:51, 2 users, load average: 0.06, 0.03, 0.05
3 targets processed in 2 seconds.
Summary: 3 successes
shmux is quite clever about this, e.g. if we do a mistake and the command fails, it stops and asks us what to do:
shmux -c oopstime localhost vuxu.org root@epona.vuxu.org hecate.home.vuxu.org
localhost! zsh:1: command not found: oopstime
shmux! Child for localhost exited with status 127
-- [PAUSED], 3 Pending/0 Failed/1 Done -- [1.7, 1.8]
?
>> Available commands:
>> q - Quit gracefully
>> Q - Quit immediately
>> <space> - Pause (e.g. Do not spawn any more children)
>> 1 - Spawn one command, and pause if unsuccessful
>> <enter> - Keep spawning commands until one fails
>> + - Always spawn more commands, even if some fail
>> F - Toggle failure mode to "quit"
>> S - Show current spawn strategy
>> p - Show pending targets
>> r - Show running targets
>> f - Show failed targets
>> e - Show targets with errors
>> s - Show successful targets
>> a - Show status of all targets
>> k - Kill a target
a
>> [0] error: localhost
>> [1] pending: vuxu.org
>> [2] pending: root@epona.vuxu.org
>> [3] pending: hecate.home.vuxu.org
Q
1 target processed (out of 4) in 89 seconds.
Summary: 3 unprocessed, 1 error
Error : localhost
Commands can be spawned in parallel when using -M max.
By default, shmux spawns the first command on its own, to check it early.
Let’s say we want to keep the outputs, so we use -o:
% shmux -M10 -o uptimes -c uptime localhost vuxu.org root@epona.vuxu.org hecate.home.vuxu.org
...
% ls uptimes
hecate.home.vuxu.org.exit 'root@epona.vuxu.org.exit'
hecate.home.vuxu.org.stderr 'root@epona.vuxu.org.stderr'
hecate.home.vuxu.org.stdout 'root@epona.vuxu.org.stdout'
localhost.exit vuxu.org.exit
localhost.stderr vuxu.org.stderr
localhost.stdout vuxu.org.stdout
Finally, the -a and -A options can be used to define
analyzers for the outputs, so see if everything worked fine.
% shmux -o uptimes -a regex -A up -c uptime ...
shmux is a useful tool for adhoc command execution as it requires no configuration and has sensible defaults.
Today is a followup on yesterdays mblaze(7) post.
This time I show how I use mblaze to send and receive patches using git and mblaze(7) as example.
First I create a patch file with git format-patch, afterwards I use mcom(1) to compose a new mail to that I deliver to my local mailbox for this example.
voidlinux.github.com@pi$ git format-patch HEAD~1
0001-The-Advent-of-Void-Day-18-mblaze-fixup.patch
voidlinux.github.com@pi$ mcom duncan@pi.lan
To: duncan@pi.lan
Cc:
Bcc:
Subject: [PATCH] mblaze advent fixup
Message-Id: <EWKLTW37CF.2MS3C7VXW22M0@pi.lan>
User-Agent: mblaze/0.2-56-g29d8946-dirty (2017-12-18)
Attachments can be added by starting a line with `#` following the
content type and the file name.
#text/plain 0001-The-Advent-of-Void-Day-18-mblaze-fixup.patch
"./snd.0" 11L, 332C written
What now? ([s]end, [c]ancel, [d]elete, [e]dit, [m]ime, sign, encrypt) m
./snd.0.mime
1: multipart/mixed size=4342
2: text/plain size=100
3: text/plain size=3552 name="0001-The-Advent-of-Void-Day-18-mblaze-fixup.patch"
What now? ([s]end, [c]ancel, [d]elete, [e]dit, [m]ime, sign, encrypt) s
First mcom(1) opened my $EDITOR with a template mail, I added the subject, the body and my patch as attachment, using the #contenttype filename syntax.
Then I write the file and close my editor (:wq), mcom(1) asks me then what to do next.
I choose [m]ime first to attach the attachment, mime is requiered for mails that contain multiple parts.
mcom(1) asks me again what to do next and I choose [s]end to deliver the mail.
On my system opensmtpd(8) delivers local mails to a maildir.
When the mail is delivered I use minc(1) to incorporate the new mails into maildirs cur directory and use mlist(1) and mseq(1) to create a new sequence to work with.
With the new sequence I can now use mless(1) to read and navigate through my mails.
voidlinux.github.com@pi$ minc ~/mail/local -q
voidlinux.github.com@pi$ mlist ~/mail/local | mseq -S
voidlinux.github.com@pi$ mless
>. 1 Wed 01:30 duncan@pi.lan [PATCH] mblaze advent fixup
From: <duncan@pi.lan>
Subject: [PATCH] mblaze advent fixup
To: duncan@pi.lan
Cc:
Date: Wed, 20 Dec 2017 01:30:05 +0100 (45 minutes, 6 seconds ago)
--- 1: multipart/mixed size=4342 ---
--- --- 2: text/plain size=100 charset="UTF-8" render="mflow -f" ---
Attachments can be added by starting a line with `#` following the
content type and the file name.
--- --- 3: text/plain size=3552 name="0001-The-Advent-of-Void-Day-18-mblaze-fixup.patch" render="mflow -f" ---
From 84eb8bea765561c2b4bb0b2b2d239393eb5c97f5 Mon Sep 17 00:00:00 2001
[...]
mless(1) saves the currently selected mail, which makes it possible to close mless(1) and then work with the last viewed mail using other mblaze(7) tools.
Because the mail contains a patch I want to apply I use mshow(1)s -t flag to get a list of the parts in the mail.
voidlinux.github.com@pi$ mshow -t
/home/duncan/mail/local/cur/1513729805.5186.pi.lan:2,
1: multipart/mixed size=4342
2: text/plain size=100
3: text/plain size=3552 name="0001-The-Advent-of-Void-Day-18-mblaze-fixup.patch"
The third part is the patch file I attached earlier, mshow(1)s -O flag to extracts a specified part to stdout by its index or by using a pattern.
I can just pipe the patch directly into git am to apply the patch and fix conflicts if necessary.
voidlinux.github.com@pi$ mshow -O . 3 | git am
Applying: The Advent of Void: Day 18: mblaze fixup
Now that the patch is applied and I flag the mail as seen and trashed using mflag(1), and update the sequence.
Updating the sequence is necessary because the filename of the mail has changed, I use mseq(1)s -f flag in this example to just fix missing mails in the current sequence, using mlist(1) again like at the beginning would get the same result.
voidlinux.github.com@pi$ mflag -ST .
voidlinux.github.com@pi$ mseq -f | mseq -S
Using mscan(1) once again shows in the second column that the mail is marked as trashed.
voidlinux.github.com@pi$ mscan
>x 1 Wed 01:30 duncan@pi.lan [PATCH] mblaze advent fixup
1 mails scanned
I hope this post gives a bit more insight on how to work with mblaze(7).
Today I want to introduce mblaze(7), a set of Unix utilities to deal with mails stored in the maildir format.
It aims to be used for both interactive usage and scripting, similar to MH or nmh.
Except that its mblaze was written from scratch to be performant and memory efficient allowing to work with large amounts of mails.
This results in a smaller and clean implementation which dropped support for (in our eyes) less useful features and improve usability.
The basic concept of mblaze is to work with sequences which are newline separated list of mail files with optional indention to represent threading.
Sequences can be used in memory by using pipes or as files which enabled further features as explained later in this post.
There are tools to create, sort, filter and manipulate sequences, other tools like mshow, maddr or magrep use those sequences to gather, address or show specific mails from sequences.
mlist(1) creates the initial sequence, It takes mail directories as argument and prints out all the mails it can find, it also has some arguments to filter mails by flags that are stored in the file name, as example -S and -s to show only seen or not seen mails respectively.
$ mlist ~/mail/
/home/duncan/mail/1505313797.1422_503.tux,U=41583:2,S
/home/duncan/mail/1505402355.860_19.tux,U=41679:2,ST
/home/duncan/mail/1505402356.860_24.tux,U=41684:2,S
/home/duncan/mail/1505402355.860_23.tux,U=41683:2,S
/home/duncan/mail/1505402356.860_25.tux,U=41685:2,S
/home/duncan/mail/1505402355.860_22.tux,U=41682:2,
/home/duncan/mail/1505402355.860_20.tux,U=41680:2,S
/home/duncan/mail/1505402356.860_26.tux,U=41686:2,S
/home/duncan/mail/1505313797.1422_502.tux,U=41582:2,ST
Most mails and MUAs work with mails in threads, mblaze has mthread(1) to group the mails in a sequence into threads.
To sort mails we use msort(1) which uses mail headers like Date or Subject to sort the sequence in the specified way.
$ mlist ~/mail/ | mthread
/home/duncan/mail//1505402355.860_19.tux,U=41679:2,ST
<voidlinux/void-packages/issues/7614@github.com>
/home/duncan/mail//1505313797.1422_502.tux,U=41582:2,ST
/home/duncan/mail//1505313797.1422_503.tux,U=41583:2,S
/home/duncan/mail//1505402355.860_20.tux,U=41680:2,S
/home/duncan/mail//1505402355.860_22.tux,U=41682:2,
/home/duncan/mail//1505402355.860_23.tux,U=41683:2,S
/home/duncan/mail//1505402356.860_24.tux,U=41684:2,S
<voidlinux/void-packages/pull/7639@github.com>
/home/duncan/mail//1505402356.860_25.tux,U=41685:2,S
/home/duncan/mail//1505402356.860_26.tux,U=41686:2,S
9 mails threaded
$ mlist ~/mail/ | mthread | msort -d
<voidlinux/void-packages/issues/7614@github.com>
/home/duncan/mail//1505313797.1422_502.tux,U=41582:2,ST
/home/duncan/mail//1505313797.1422_503.tux,U=41583:2,S
/home/duncan/mail//1505402355.860_20.tux,U=41680:2,S
/home/duncan/mail//1505402355.860_23.tux,U=41683:2,S
/home/duncan/mail//1505402356.860_24.tux,U=41684:2,S
<voidlinux/void-packages/pull/7639@github.com>
/home/duncan/mail//1505402356.860_25.tux,U=41685:2,S
/home/duncan/mail//1505402356.860_26.tux,U=41686:2,S
/home/duncan/mail//1505402355.860_19.tux,U=41679:2,ST
/home/duncan/mail//1505402355.860_22.tux,U=41682:2,
9 mails threaded
To avoid creating and piping sequences every time we can use mseq(1) to save and manipulate mail sequence files.
If the sequence is stored as file the mblaze utilities can use the sequence from the file to address mails by index numbers and mmsg(7) selectors.
$ mlist ~/mail/ | mthread | msort -d | mseq -S
9 mails threaded
$ cat ~/.mblaze/seq
<voidlinux/void-packages/issues/7614@github.com>
/home/duncan/mail//1505313797.1422_502.tux,U=41582:2,ST
/home/duncan/mail//1505313797.1422_503.tux,U=41583:2,S
/home/duncan/mail//1505402355.860_20.tux,U=41680:2,S
/home/duncan/mail//1505402355.860_23.tux,U=41683:2,S
/home/duncan/mail//1505402356.860_24.tux,U=41684:2,S
<voidlinux/void-packages/pull/7639@github.com>
/home/duncan/mail//1505402356.860_25.tux,U=41685:2,S
/home/duncan/mail//1505402356.860_26.tux,U=41686:2,S
/home/duncan/mail//1505402355.860_19.tux,U=41679:2,ST
/home/duncan/mail//1505402355.860_22.tux,U=41682:2,
Now that the sequence is saved we can continue can use mscan(1) a tool to print one line message lists including the subject, the date and a visual representation for the flags.
$ mscan
\_ <voidlinux/void-packages/issues/7614@github.com>
x 2 Sun Sep 10 gravicappa Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
3 Sun Sep 10 Lain Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
4 Thu Sep 14 Enno Boland Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
5 Thu Sep 14 Dominic Monroe Re: [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EULA (#7657)
6 Thu Sep 14 lemmi Re: [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EULA (#7657)
\_ <voidlinux/void-packages/pull/7639@github.com>
8 Thu Sep 14 Michael Gehring Re: [voidlinux/void-packages] libcaca: add (optional) support for imlib2 (#7639)
9 Thu Sep 14 newbluemoon Re: [voidlinux/void-packages] libcaca: add (implicit) support for imlib2 (#7639)
x 10 Thu Sep 14 Michael Gehring Re: [voidlinux/void-packages] libdockapp: Corrected incorrect entry in shlibs (#7652)
. 11 Thu Sep 14 lemmi [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EULA (#7657)
11 mails scanned
The first column is for flags, x is for Trashed mails, and . (dot) for unseen mails, the second column is the index of the mail in the sequence.
mscan can use the previously mentioned mmsg(7) syntax to address or select mails.
In this example the first one just addresses two mails by their index, the second example selects a range of mails starting and ending at the specified index.
$ mscan 2 5
x 2 Sun Sep 10 gravicappa Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
5 Thu Sep 14 Dominic Monroe Re: [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EULA (#7657)
2 mails scanned
$ mscan 2:5
x 2 Sun Sep 10 gravicappa Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
3 Sun Sep 10 Lain Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
4 Thu Sep 14 Enno Boland Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
5 Thu Sep 14 Dominic Monroe Re: [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EULA (#7657)
4 mails scanned
The next tool is mshow(1) which renders mails or extracts attachments.
$ mshow 2
From: gravicappa <notifications@github.com>
Subject: Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
To: voidlinux/void-packages <void-packages@noreply.github.com>
Cc: Duncan Overbruck <duncaen@voidlinux.eu>, Comment <comment@noreply.github.com>
Date: Sun, 10 Sep 2017 09:30:36 -0700 (14 weeks, 1 day, 1 hour ago)
Reply-To: voidlinux/void-packages <reply+002aecdf7dfdc8d5ee7bc8a57eb08b436b6d3af844c59c4192cf0000000115cd2aac92a169ce0f49ca87@reply.github.com>
--- 1: multipart/alternative size=2477 ---
--- --- 2: text/plain size=258 charset="UTF-8" render="mflow -f" ---
It shows cyrillics correctly but inputting whose with keyboard yields nothing.
--
You are receiving this because you commented.
Reply to this email directly or view it on GitHub:
https://github.com/voidlinux/void-packages/issues/7614#issuecomment-328354106
mless(1) is a small wrapper around less that lets you page through your sequence.
On the top it prints a few lines from mscan with the current mail highlighted and on the bottom it shows the content of the mail.
You can now use :n and :p to navigate through mails.
$ mless
x 3 Sun Sep 10 gravicappa Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614
4 Sun Sep 10 Lain Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614
> 5 Thu Sep 14 Enno Boland Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614
. 6 Thu Sep 14 lemmi [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EU
7 Thu Sep 14 Dominic Monroe Re: [voidlinux/void-packages] Replace caddy with wedge in light of caddy's
8 Thu Sep 14 lemmi Re: [voidlinux/void-packages] Replace caddy with wedge in light of caddy's
From: Enno Boland <notifications@github.com>
Subject: Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
To: voidlinux/void-packages <void-packages@noreply.github.com>
Cc: Duncan Overbruck <duncaen@voidlinux.eu>, Comment <comment@noreply.github.com>
Date: Wed, 13 Sep 2017 23:15:15 -0700 (13 weeks, 4 days, 17 hours ago)
Reply-To: voidlinux/void-packages <reply+002aecdfbf62a2c14f84705a7fd3c31678cfae556dcc03ee92cf0000000115d1e07392a169ce0f49ca87@reply.github.com>
--- 1: multipart/alternative size=2827 ---
--- --- 2: text/plain size=197 charset="UTF-8" render="mflow -f" ---
Closed #7614 via #7633.
--
You are receiving this because you commented.
Reply to this email directly or view it on GitHub:
https://github.com/voidlinux/void-packages/issues/7614#event-1248561716
~
~
mless 2 (message 3 of 12)
Another tool is mpick(1) which can be used to write extensive filters for mail sequences.
$ mpick -t 'subject =~~ "dmenu"' | mscan
x 3 Sun Sep 10 gravicappa Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
4 Sun Sep 10 Lain Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
> 5 Thu Sep 14 Enno Boland Re: [voidlinux/void-packages] dmenu-4.7 doesn't allow cyrillic input (#7614)
11 mails tested, 3 picked.
3 mails scanned
In the next example mpick only picks mails between two dates and tests if the replied flag is set or the seen flag is not set.
$ mpick -t 'date >= "2017-09-01" && date < "2017-10-01" && (replied || !seen)' | mscan
. 6 Thu Sep 14 lemmi [voidlinux/void-packages] Replace caddy with wedge in light of caddy's new EULA (#7657)
11 mails tested, 1 picked.
1 mails scanned
This is just a very small example, mblaze is capable of a lot more and has great man pages that are worth reading, see mblaze(7) and the git repository as starting point if you want to learn more about it.
There are many ways to see what’s going on your system, such as top(1), htop(1), atop(1). However, these tools only show the current state of the system, and it’s not so easy to see how the data changes.
dstat(1) works differently: it prints a line every second with some system stats you can configure. By default, it shows CPU usage, disk I/O, network traffic, paging, and context switches:
% dstat
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
45 9 45 1 0| 284k 181k| 0 0 | 18k 36k| 754 2181
28 6 65 1 0| 0 0 |4698k 222k| 0 0 |4123 17k
34 8 58 0 0| 0 0 |4730k 220k| 0 0 |5253 20k
29 8 62 1 0|4096B 1080k|4640k 215k| 0 0 |4383 18k
37 7 38 17 0| 0 15M|4844k 219k| 0 0 |5532 21k
31 8 30 32 0| 336k 6840k|5153k 232k| 0 0 |4383 17k
...
For Void development, I like to run this configuration; showing per-core CPU usage, memory usage, process spawn rate and I/O.
% dstat --cpu-use -mpr
---------per-cpu-usage--------- ------memory-usage----- ---procs--- --io/total-
0 1 2 3 4 5 6 7 | used free buff cach|run blk new| read writ
4 2 1 1 1 1 1 1| 550M 2510M 2823M 1315M| 0 0 4.4|6.42 0.93
1 0 0 0 0 1 0 0| 550M 2510M 2823M 1315M| 0 0 1.0| 0 0
2 2 1 1 0 0 0 1| 551M 2508M 2823M 1315M| 0 0 20| 0 0
1 0 0 0 0 0 0 0| 551M 2508M 2823M 1315M| 0 0 0| 0 0
0 0 0 0 0 0 0 0| 551M 2509M 2823M 1315M| 0 0 0| 0 0
2 0 0 0 0 1 0 0| 551M 2509M 2823M 1315M| 0 0 0| 0 0
This allows us to easily detect if builds are not optimally parallelized,
or whether we run into memory limits.
And process spawn rate detects if a ./configure script runs. ;)
dstat includes a huge list of probes it can display, just to list a few: battery usage, free disk, MySQL/InnoDB stats, qmail queue size, NFS traffic, NTP stats, WiFi measurements, ZFS information.
It’s a very versatile tool, and because it works via the console, you can also easily run it over SSH.
A tool with many uses is pv(1), the ‘pipe viewer’. Essentially, you can put it between any pipe and you’ll see statistics on its throughput.
For example, we can measure the speed of /dev/urandom:
% pv < /dev/urandom > /dev/null
168MiB 0:00:01 [ 167MiB/s] [<=> ]
Or look how fast we can extract a tar.xz file:
% xzcat big.xz | pv | tar xf -
Or copy a whole disk to a remote host, with a progress bar:
# dd if=/dev/sdb | pv | ssh me@remote dd of=/dev/sdc
pv has a few nifty flags, for example, it also can count
lines instead of bytes. So we can build a progress bar for
a find/xargs call
(or rather,
lr/
xe):
% find /tmp -name '*.png' | pv -l | xargs -P4 -n1 pngcrush -ow
(Or even better, use find -print0 and pv -0.)
Finally, pv also can limit the bandwidth, which can be useful if you
want to limit transfer rates to lower strain on the system, for example,
and buffer the input, which is useful to ensure a consistent write rate.
Time for some fun! Surely you know what an anagram is: a rearrangement of the letters of a sentence to yield a different sentence. For example, ELVIS has the same letters as LIVES, and THE MORSE CODE has the same letters as HERE COMES DOTS.
How can we find such anagrams? With our computer! Today, we’ll use the tool an(6) for that.
By default, it will list all anagrams it finds, with the longest word first:
% an butterfly |head
butterfly
fluttery b
fluttery B
utterly bf
utterly f b
utterly f B
utterly b F
utterly F B
flutter by
flutter Yb
We can limit the minimum word length with -m to filter out the
single letters:
% an -m3 butterfly |head
butterfly
butter fly
belfry tut
belfry Tut
turfy belt
lefty Burt
lefty Brut
beryl tuft
Betty furl
Beryl tuft
When we are just looking for inspiration, -w will list all words
that are contained in the sentence:
% an -w butterfly |head
butterfly
fluttery
utterly
flutter
buttery
turtle
tufter
butter
butler
belfry
If we want to make a more complicated anagram, it also help if we can
mark some letters as used, with -u:
% an -m3 -u Merriest 'Christmas Tree'
chats
chat's
ACTH's
Ah, yes: CHRISTMAS TREE and MERRIEST CHATS.
Finally, an can also test if two sentences are anagrammatic:
% an -t 'Atomic Tests are fun idea' 'United States of America'
Atomic Tests are fun idea can be made from United States of America
Finally, if you are looking for anagrams in other languages,
you can pass a different dictionary with -d.
Void Linux includes e.g. words-de.
Day 14, and a little treat for you pulseaudio users out there. Two underappreciated packages for an underappreciated workflow.
I don’t always use pulseaudio. But when I do, I don’t like opening pavucontrol for any reason. After all, I live in the terminal for almost everything, and switching from my text-mode audio players to the GUI just to change volumes (or route audio to new players) just seems like a waste.
So that’s where PAmix and pulsemixer come in. They are only useful if you
use pulseaudio, but it solves the problem of needing a GUI to easily tinker
with pulse volume, set where audio gets sent, and it does it all in two super
intuitive interfaces.
PAmix is a fun little interface that tries to map 1:1 from pavucontrol to
an ncurses interface. The keybindings are intuitive, there is support for hjkl
as well as arrow keys, and interaction is what you expect.

PAmix occasionally segfaults (but has gotten much better about that), but is very fast to start up again with a quick up-arrow enter in your (not dash) shell.
Meanwhile, there is a python implementation of the same functionality, this one
with a different set of goals. For pulsemixer, there are two interfaces. One
is suitable for scripting, with commands such as pulsemixer --change-volume +5,
and a ncurses interface. This interface isn’t modeled after pavucontrol, but
takes freedoms some people might appreciate.
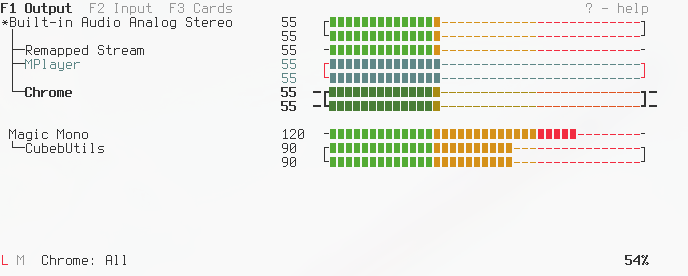
To learn more, you can read the PAmix README or the pulsemixer README
Either way, there is no longer any need to use a GUI to manage your pulseaudio system. Enjoy your newfound power!
